
Reaktive Programmierung ist bei der Entwicklung von Apps unumgänglich geworden. Fast alle Digitalunternehmen nutzen mittlerweile Modelle, die in irgendeiner Weise reaktiv sind. Das können schon Frameworks mit den einfachsten Aktorenmodellen sein. Oder aber es handelt sich um eine Hundertschaft von Futures/Promises mit einer unterschiedlichen Dichte an Programmierschnittstellen bis hin zu enormen FRP (Functional Reactive Programming) Frameworks, die ein komplett neues Programmierparadigma einführen und die Architektur einer App gleich im Prozess formen.
Der ein oder andere mag sich fragen: “Wann ist das dann passiert? Wie konnte ich das verpassen?” – und vor allem – “Ist meine objektorientierte MVC App von 2012, die in Objective-C geschrieben wurde, nicht auch irgendwie reaktiv?”
Der Sinn von Apps war schon immer derselbe: eine Nutzerschnittstelle zu präsentieren, die auf Änderungen in der Außenwelt reagiert. Das können sowohl durch den Nutzer ausgelöste Interaktionen mit der App sein als auch externe Vorkommnisse wie etwa Datenveränderugen auf dem Server. In diesem Sinne waren Apps schon immer reaktiv. Das heißt aber noch lange nicht, dass sie auch reaktiv programmiert waren. Und dass den Nutzern die Anwendung immer so reaktiv vorkam, wage ich hier auch mal zu bezweifeln (oder irre ich mich da?). Mit dem Fortschritt wächst auch der Anspruch der Nutzer. Starren wir heute auf unseren frisch geposteten Facebook-Beitrag, gebannt darauf wartend, dass sich die ersten Likes einstellen, klicken wir nicht mehr alle anderthalb Sekunden auf den Refresh-Button, wie wir es noch vor ein paar Jahren getan hätten. Denn wir wissen, dass die App inzwischen – fast kommt es uns heute wie selbstverständlich vor – automatisch auf neue Daten reagiert, sobald diese einfließen.
Reaktive Programmierung ist also nicht nur irgendeine neumodische Art, Apps zu programmieren, sondern offensichtlich eine, die essentiell geworden ist. Der Sprung von objektorientierten Apps, die auf Nachrichten reagieren, zu reaktiven Apps, die auf Datenflüsse reagieren, wurde maßgeblich durch die immer größer werdenden Anforderungen der Nutzer ausgelöst. Die alten objektorientierten Delegation Patterns konnten diesen Anspruch in asynchronen, unbestimmten Umgebungen einfach nicht mehr erfüllen. Zum Glück haben wir dafür jetzt die FRP Frameworks, die diese Lücke rühmlich füllen.
Das Problem der Status-Synchronisierung
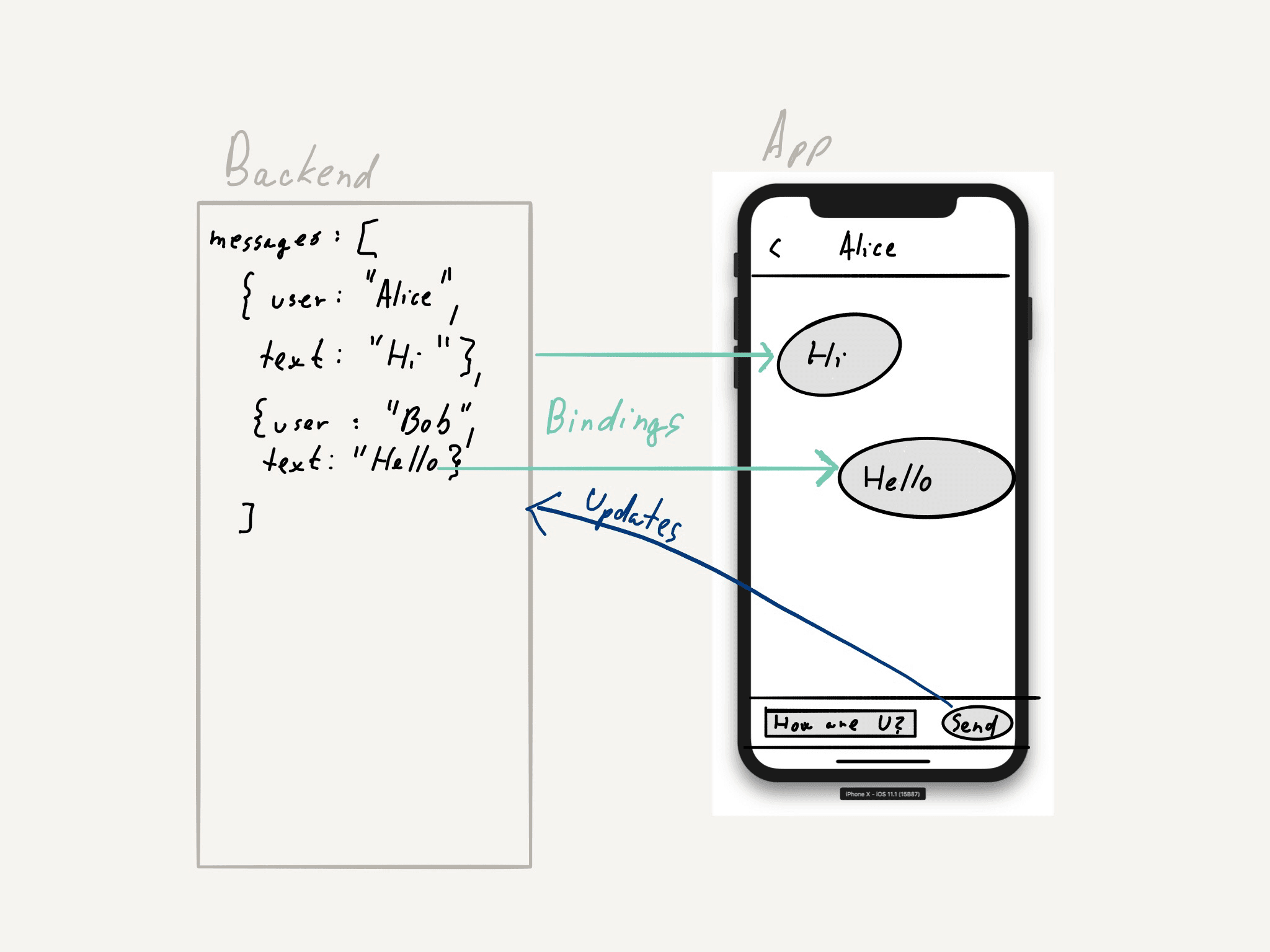
Ein klassischer Job eines Programmierers ist es, den wahrgenommenen Status des Nutzers mit dem des Modells dahinter synchron zu halten. Denken wir zum Beispiel mal an einen einfachen Messenger-Dienst. Was passiert, wenn ich eine Nachricht schreibe und auf Senden drücke? Dann wandert die Nachricht an genau diesem Punkt vom View Layer in den Model Layer und von dort anschließend zum Server. Und wenn jemand anderes mir eine Nachricht schickt? Dann vollzieht sich eine Datenveränderung auf dem Server, die meine App aufnehmen und in einem Update in der Bedienoberfläche darstellen muss. Wir brauchen also einen Code, in dem wir beide Fälle unterbekommen.
Ein Ansatz könnte dabei zum Beispiel eine arbiträre Synchronisierungslogik sein. Das würde bedeuten, dass ein Controller den Text vom Textfeld abholt, sobald ich den Senden-Knopf gedrückt habe, und im Model Layer die nötigen Änderungen vollzieht – wie etwa entsprechende Änderungen in der Datenbank. Es liegt auch in der Verantwortung des Controllers, die Nachricht an den Server weiterzuleiten. Die Aktion in umgekehrter Richtung – also eine Nachricht zu erhalten und die entsprechende Änderung in der Bildschirmanzeige – wird ebenfalls vom Controller in mehreren Schritten durchgeführt. Im Extremfall teilen sich die beiden Zweige “Nachricht senden” und “Nachricht empfangen” kaum einen Code. Der Controller hat dabei uneingeschränkte Handlungsfreiheit: Eine Implementierung könnte z.B. nach jedem getippten Buchstaben synchronisieren, eine andere adressiert eine Änderung in der Anzeige erst, nachdem Senden gedrückt wurde.
Reaktive Programmierung kommt dann ins Spiel, wenn wir aufhören, unsere App als ein Set an Usecases zu sehen, für die jeweils ein Zweig des Codes zuständig ist. Stattdessen sollten wir die Nutzerschnittstelle als einen Status annehmen und den der “Welt” (also der Datenbank oder des Servers) als anderen. Der Job des Programmierers ist es, diese beiden zu synchronisieren. Wir müssen also über Daten und deren Verbreitung (d.h. Datenfluss) nachdenken. Wie stelle ich sicher, dass jedes Mal, wenn eine Nachricht auf dem Server erscheint, auch eine in der Nutzeranzeige auftaucht? Wie kann ich sicher sein, dass eine Nachricht, die in der Nutzerschnittstelle als gesendet angezeigt wird, auch in der Datenbank bzw. auf dem Server eine Statusänderung erreicht? Hier bedarf es der Datenbindung, die es dem Programmierer erlaubt, den Datenfluss mit einer deklarativen Beschreibung zu versehen und so zu lenken. Effektiv macht das aus der App einen Automaten, der, einmal korrekt installiert, künftig für alle eintreffenden Inputs genau die passende Handlung vornimmt.
Der reaktive Rahmen bildet die Grundlage für die Datenbindung. Da wir uns nur auf Datenflüsse konzentrieren müssen, können wir mehr beschreibenden Code programmieren und so die meisten Nebenwirkungen vermeiden. Es wirkt daher ganz so, als sei bidirektionale Datenbindung die ideale Lösung für alles. Der View Layer synchronisiert immer mit dem Model Layer, der Model Layer immer mit dem View Layer, alle sind glücklich. Dieser Ansatz wurde vor ein paar Jahren durch das ReactiveCocoa Framework in der alten Objective-C-Version populär. Allerdings hat sich herausgestellt, dass in der bidirektionalen Datenbindung die Definition eines einzigen Graphen für die gesamte App problematisch ist. Unidirektionale Bindungen, die auf einem FRP Framework basieren, wurden daher zum Standard bei der reaktiven Programmierung. Bindungen in einer Richtung funktionieren in solchen Situationen gut, in denen wir annehmen, das ein Status (typischerweise der der Nutzerschnittstelle) von einem anderen Status (typischerweise dem des Models) abgeleitet ist.
Das ist im Kern der Paradigmenwechsels, den wir in den letzten fünf Jahren beobachten konnten. Er brachte neue Frameworks, neue Wege der App-Architektur – und vor allem bessere Apps. Wer’s noch genauer wissen will, für den tauche ich im Folgenden noch ein bisschen tiefer in die Raffinessen von FRP inkl. der Plattformen, auf denen wir es anwenden, ein.
Functional Reactive Programming
Yaron Minsky beschreibt FRP-Programme in seinem Blog bei Jane Street als Abhängigkeitsgraphen von Signalen. Diese Signale sind entweder externe Inputs oder Signale, die von anderen abgeleitet wurden, die bereits im System definiert sind.
Pure Monadic FRP
In dieser voll ausgestatteten FRP-Version kombinieren Signal Combinators ‘map’ und ‘map2’ für einfache Signaltransformationen, ‘join’ für die Dynamik und ‘foldp’ für History Sensitivity (d.h. für die Möglichkeit, über vergangene und aktuelle Werte von Signalen verfügen zu können). Leider ist die Platzeffizienz von rein monadischem FRP schlicht und ergreifend inakzeptabel. Das macht es unmöglich, den Programmierstil in der Praxis anzuwenden.
Pure Applicative FRP
Rein applikatives FRP umgeht ein paar der Probleme, die beim Evaluieren desselben Ausdrucks zu unterschiedlichen Zeitpunkten auftreten, indem es auf die Dynamik (und den ‘join’ Operator) verzichtet. Dieser Ansatz stammt von Elm und mit ihm können durch die Kombination von React und Redux ganz ähnliche Ergebnisse wie beim rein monadischen FRP erzeugt werden. Seine Anwendung findet das Ganze bei Websites. Auf mobilen Plattformen hat sich Pure Applicative FRP leider als problematisch erwiesen, da sich VDOMs bei mobilen Bedienoberflächen nicht wirklich gut machen.
Impure Monadic FRP
Impure Monadic FRP ist sozusagen der Mainstream-Ansatz. Er wurde maßgeblich durch die Rx-Frameworks-Familie und ReactiveSwift verbreitet und enthält die meisten Funktionen, die wir am Pure Monadic FRP schätzen. Mit einer Ausnahme: Wird der gleiche Ausdruck zu unterschiedlichen Zeitpunkten evaluiert, können unterschiedliche Werte ausgegeben werden. Das lässt in der Tat die Bearbeitung eines jeden Signals zu einer möglichen Fehlerquelle werden. Dennoch ist dieser Ansatz die am weitesten verbreitete Anwendung von FRP. Wir benutzen es in der App-Entwicklung bei MVVM- und MVP-Architektur sowie bei Backend-Entwicklungen. Die Kombination mit Legacy-Code und bereits bestehenden objektorientierten Frameworks ist meist problemlos.
Self Adjusting Computation
Dieser kleine Twist am FRP-Ansatz, der erstmals im OCaml Framework Incremental erschien, hat eine Menge zu bieten. Er lässt die History Sensitivity (den ‘foldp’ Operator) beiseite, sodass man sich allein auf aktuelle Signalwerte verlassen muss. Im Gegenzug für diese Entbehrung erhält man ein sehr stabiles und berechenbares System ohne reaktive Glitches. Chris Eidhof et al. suchen bei ihrer Forschung nach noch weiteren Erkenntnissen zu Redux-Speichern mit UIKit und einem Swift Port im Incremental-Framework. Als dieser Artikel veröffentlicht wurde, wurde bereits die erste Incremental App beim AppStore eingereicht. Vielleicht können wir diesen Ansatz in Zukunft nutzen, um endlich auch mobil einen unidirektionalen Datenfluss zu haben.






